This is a static site generated with Template Toolkit plus some custom plugins for easier generation of the picture pages.
The site uses http (not https) for much the same reasons as given by n-gate. See also Let's not Encrypt.
Email from fail2ban
2023-04-25
One of fail2ban's tasks on my VPS "rolly" is to open ports for me when I'm "on the road". The ports are for wireguard, SSH and some other services. The specific thing I do to trigger port opening isn't important here, suffice to say that I cause something to appear in a log file on rolly. fail2ban detects the "something" and in response opens the ports on rolly for my laptop's (or phone's) current IP address.
It nearly always works well but has lacked one "nice to have" feature. Sometimes when it doesn't work I'm left wondering whether the string didn't make it into the log file or whether it did and fail2ban somehow failed to respond. (Most recently it was because I'd opened the port to my ipv4 address and then unwittingly attempted to connect over ipv6.) What would be nice would be an email from fail2ban confirming that it had worked and saying what IP address it had allowed in. Also, in the unlikely event that someone else causes the string to go into the log file, it would be nice to know about that too.
How is fail2ban configured to send email? Looking around in fail2ban's documentation didn't lead to enlightenment. After web searches and trial and error I found out how to do it, or at least a way to do it.
On my debian server, fail2ban's configuration is under /etc/fail2ban/. Under action.d/ are several files with names matching mail*conf or sendmail*conf. They look like they're to do with sending email, but which kind to use?
One directory up contains jail.conf which
contains this:
# E-mail action. Since 0.8.1 Fail2Ban uses sendmail MTA for the
# mailing. Change mta configuration parameter to mail if you want to
# revert to conventional 'mail'.
mta = sendmail
Ignore the "MTA" part, it really means the sendmail(1) program, as typically supplied by whatever MTA you're using (in my case postfix). I.e. to send email, fail2ban runs whatever is the locally installed sendmail program and supplies the program with the email text on its standard input. OK, how to make that happen from our fail2ban config?
We make it happen with a line added to the "jail" that opens ports.
[open-ports]
enabled = true
filter = open-ports
action = add-to-ipset[name=ssh, bantime=25200, comment=f2b]
sendmail-open[name="open-ports"]
logpath = /var/log/some-log-file.log
maxretry = 1
bantime = 25200
The second line under "action" causes fail2ban to send email when it
opens ports. The installed sendmail.conf file defines an email
template that says "The IP <ip> has just been banned". But I'm
using fail2ban in this case in reverse - a "ban" opens ports and
"unban" closes them again. So I added my own action file to make
the emails more clear. It's a little long so this shows only the
"actionban":
actionban = printf %%b "Subject: Opened for <ip>
X-tag: alert
Date: `LC_ALL=C date +"%%a, %%d %%h %%Y %%T %%z"`
From: <sendername> <<sender>>
To: <dest>\n
<name> opened ports for\n
[ <ip> ]\n
on <fq-hostname> after <failures> requests.\n
Regards,\n-- \nFail2Ban" | <mailcmd>
The result is almost all I wanted. When I open ports from
my laptop or phone, fail2ban sends me an email saying
open-ports opened ports for
[ 2805:7a0c:a3:6c3c:9d11:5750:f917:da1e ]
on rolly.lokal after 1 requests.
Regards,
--
Fail2Ban
There are two things I'd like but don't know how to do. One is that I'd prefer the closed-ports email to appear at some configurable interval before the ports are actually closed. The other is what happens in the case that I renew the port-opening while the ports are still open to the same client ip address.
In the latter case, what fail2ban does is silently update the expiry time of the "ban". It doesn't send an email. Perhaps to be expected since I'm using fail2ban in a way probably not anticipated. I'm happy enough to get timely and helpful emails confirming that my new port-opening requests are received and understood.
Dovecot and full text search
2022-09-21
Thanks to 'colo' on irc, I learned how to improve searching in mutt. Here are the steps to make it work in Debian 11 "bullseye", most of which comes from 'colo', possibly with my mistakes added.
Install packages:
# apt-get install dovecot-fts-xapian catdoc
Download decode2text.sh into /usr/local/bin.
Configuring dovecot requires several changes. To confine indexing to
actual mail users, I set the *_valid_uid
values to suit. Later in the same file there's also
mail_plugins to set.
first_valid_uid = 1000
last_valid_uid = 1017 # or whatever suits
...
mail_plugins = fts fts_xapian
Add this conf file.
plugin {
fts = xapian
fts_xapian = partial=3 full=20 verbose=0
fts_autoindex = yes
fts_enforced = yes
fts_autoindex_exclude = lists
fts_autoindex_exclude2 = trash
fts_decoder = decode2text
}
service indexer-worker {
vsz_limit = 2G
}
service decode2text {
executable = script /usr/local/bin/decode2text.sh
user = dovecot
unix_listener decode2text {
mode = 0666
}
}
Restart dovecot and run
# doveadm index -A -q \*
I'd never run that before and it took about 20 minutes to complete. It logs about what it's doing to the mail log, typically (and in my case) /var/log/mail.log. Once it's complete, you should be able to report on mail for the user 'fred' that contains the string "aardvark" with this:
# doveadm fts lookup -u fred BODY aardvark
which reports matching folders and message numbers in this form,
some/folder: 9,19:20,732
Annoyingly, it also reports folders with 'no results' so a little 'grep -v' is in order to discard the clutter.
On the advice of dovecot-fts-xapian's README, I added a daily cron job:
#!/bin/sh
chronic doveadm fts optimize -A
Something that didn't work was running doveadm fts rescan. Rescanning deleted the indexes under /var/mail/fred/xapian-indexes, requiring a rerun of doveadm index. The man page for doveadm-fts(1) warns "Note that currently most FTS backends do not implement this properly, but instead they delete all the FTS indexes." That applied to me.
With that all set up, in mutt running as an imap client, I can send search queries to the server with patterns like =B aardvark. Results appear within a second. A limitation is that mutt offers no way to search over all folders, only in the current folder.
Trackpad tap-to-click
2021-08-14
My Lenovo X270 has a poor quality keyboard. The small keys in the navigation cluster at bottom right have a tendency to come adrift. My previous laptop, an X201i, was generally sturdier and better. So I think of trying a different manufacturer next time.
But ThinkPads have a feature I like a lot, the physical mouse buttons fitted to the trackpad. Can trackpads be made to do "tap to click"? Does tapping work well enough to replace hardware buttons?
The answer to my first question is yes, via a libinput configuration fragment:
Section "InputClass" Identifier "libinput touchpad catchall" MatchIsTouchpad "on" MatchDriver "libinput" Option "Tapping" "on" Option "TappingDrag" "on" Option "TappingButtonMap" "lmr" EndSection
The answer to my second question isn't so clear cut. I've found tapping less convenient and reliable than pressing buttons. But it's workable and my temptation to stray from ThinkPads has increased.
Wireguard
2020-10-28
This item is what I wish I could have found when attempting my first wireguard vpn, having failed to make much sense of the official introductory material, e.g. the quick start. My scenario is: I rent a VPS named rolly with a static address and excellent network connectivity, well suited to become a vpn server. My laptop argon is a vpn client. Without futher ado:
On server and client alike, generate the host's keys with
$ wg genkey | tee wg-private.key | wg pubkey > wg-public.key
Configuration files for keys and peers, which should be readable by
root only:
[Interface]
PrivateKey = <rolly's private key>
ListenPort = 51820
[Peer]
# argon
PublicKey = <argon's public key>
AllowedIPs = 10.16.61.2/32
[Interface]
Address = 10.16.61.2/24
PrivateKey = <argon's private key>
[Peer]
# rolly
PublicKey = <rolly's public key>
AllowedIPs = 0.0.0.0/0
Endpoint = rolly:51820
PersistentKeepalive = 25
Note the server knows its clients by specific AllowedIPs while the client doesn't care about the server's AllowedIPs. It appears that in the server's config, each client must have an AllowedIPs value that is distinct from other clients and those values may not overlap. I've taken the simple way, of giving each client its own /32 address.
I use Debian's venerable ifupdown to manage the vpn's interfaces. This is based on the Debian wiki.
auto wg0 iface wg0 inet static address 10.16.61.1 netmask 255.255.255.0 pre-up ip link add $IFACE type wireguard pre-up wg setconf $IFACE /etc/wireguard/$IFACE.conf post-down ip link del $IFACE
For the client, I took advice from #wireguard on freenode which resulted in this nicely succinct iface stanza:
iface wg0 inet manual pre-up wg-quick up $IFACE post-down wg-quick down $IFACE
At this point, once rolly and argon both have their wg0 interfaces up, they should be able to communicate with each other by their 10.16.61.* vpn addresses. However, argon won't be able to see anything else until rolly forwards argon's traffic to the internet with SNAT.
It isn't really a Wireguard concern so I'll just outline how I did this with Shorewall on rolly. Switch on IP forwarding, add the wg0 interface and add the vpn zone. Set policy to allow vpn traffic to the firewall and outwards. Add a snat file for vpn traffic out to the internet. With that set up, traffic between argon and the internet goes via rolly, hidden from observers between argon and rolly.
For traffic between client and server there is no longer any need for ssh tunnels. The vpn has another advantage while using mobile data. I discovered that at least one science blog is considered "adult only" material by my mobile data provider. For permission to view it I must give my credit card number to the provider, probably for inclusion in some poorly secured corporate database. Or I can use my vpn and ignore their "safety" controls.
Happily, there is also a Wireguard app for LineageOS. Once added as another peer on rolly, my phone too can forgo the benefits of safety. And my phone and laptop can communicate with each other over the vpn even when they are on different networks.
A smartphone advenure
2020-07-26
On July 14th I acquired my first smartphone. My used LG G5 has a headphone socket, a replaceable battery and, more important for me, is a model with a supported LineageOS build. To give it a basic test I tried it out with Android still on it but without a Google account and without a SIM, which meant it wouldn't do much.
Satisfied the phone wasn't obviously defective, I managed to install LineageOS. There were some bumps on that road.
Unlocking the bootloader requires an LG 'developer account'. If you register on LG's web site with a strong password, the subsequent "extra information" page will say you've given an incorrect password and let you go no further. I created another account, this time with a weaker password (alphanumeric only) and succeeded in getting the necessary unlock.bin file.
The next difficulty was downloading TeamWin's recovery image. Their web server silently sabotages the download if you use wget without the referer set to their satisfaction. A web search let me in on this secret and I was able to download a valid recovery image. (Since I installed, Lineage updated their installation instructions and now tell you to download a Lineage recovery image.)
The third obstacle was how to boot into recovery mode. It seems that writing the recovery image doesn't "take" unless, counterintuitively, the phone is powered off between the write and the next boot. But I found no apparent way to power off at that point because the power button was ignored. I resorted to pulling the battery out while the phone was still on.
LineageOS was now installed. I think it's great that its contributors supply an OS that can be used at no cost and which provides an alternative to the Google-Apple duopoly. So I say this as information, not as a complaint: LineageOS has some glaring bugs.
The screen lock mechanism, once chosen, couldn't be changed. I was stuck with nothing but a swipe gesture to "unlock" the screen. My attempts to set a lock resulted in the phone becoming unresponsive and going into a boot loop. I ended up booting into recovery mode again and deleting all settings and data.
This time around I chose a pin lock that I'll leave well alone. A less serious but intrusive bug is that "screen blank" = "phone locked". You cannot separate the two. There is a setting to delay locking until some time after the screen blanks but its effect is nil. So I unlock the phone a lot because it locks a lot.
On the more positive side, I discovered termux. This gives me the means to open an ssh tunnel to my mail server, avoiding the risks that come with opening ports to the world. Unfortunately LineageOS's built-in mail app silently and repeatedly overwrote my custom port number. I found better luck with "K-9 Mail". Better yet, mutt is available via termux so I can, with some difficulty, use the One True Mail Client on my phone with its tiny on-screen keyboard.
Since I'd managed to get this far without bricking the phone, it was time to install a SIM and start paying for service. This part went easily, number portability and all. So for the time being at least, I have a fully functioning smartphone without being subject to the Google panopticon. Though it wasn't a monetary cost, I did have to pay in time and effort. Perhaps in future the cost will fall and alternatives to the duopoly will become more widely accessible.
Reminding with 'at'
2020-06-29
In the war on forgetting a useful ally is the 'at' utility to run a command in the future. For short term (minutes to hours) reminders I run 'at' via a script called egg-timer. The command that runs in the future is zenity, to pop up a dialogue.
Longer term (hours to months) reminders are more complicated. Some go into a remind file managed with wyrd. This way is best for events that repeat, so I have some chance of remembering them anyway, such as the next recycling collection day.
Unusual events that are due in days or months are the most difficult to deal with. 'remind' can do these of course but for me it's a little too gentle. Once I've seen the reminder, wyrd is silent and I'm in danger of forgetting instead of dealing. For these cases an email is better because, until I delete it, the reminder stays in my inbox. To schedule these emails I use a script imaginatively called email-at.
$ email-at "Negotiate with alien invasion fleet." now + 1 month warning: commands will be executed using /bin/sh job 687 at Aug 4 12:19:00 2020
Naturally it's desirable to be able to view the reminders that are queued up to be sent. The output of the 'atq' command is not well suited.
$ atq 687 Tue Aug 4 12:19:00 2020 a donym 690 Sat Jul 11 22:00:00 2020 a donym
From that I can see something is due on July 11th. With 'at -c 690' I can even see what it is, but that's clumsy. I use a two-part solution. One part is a C program that lists the contents of /var/spool/cron/atjobs. The other is a perl script that invokes the C program and turns its output into something more helpful:
$ atv Jul 11 Sat 22:00 BST 690 Meet with leaders of the military-industrial complex. Aug 4 Tue 12:19 BST 687 Negotiate with alien invasion fleet.
The perl script shows the subject of each pending email and orders by date, not by job id. The C program is installed with setgid so that it can read the atjobs directory.
$ ls -ld /var/spool/cron/atjobs drwxrwx--T 2 daemon daemon 4096 Jun 25 09:00 /var/spool/cron/atjobs $ ls -l /usr/local/bin/lsat -rwxr-s--x 1 root daemon 17024 Jun 2 20:16 /usr/local/bin/lsat
One more script takes care of removing pending mail from the 'at' queue. email-at creates a file for the email text under /var/tmp. The file would be orphaned by the regular 'atrm' program so a wrapper script deletes the file before it calls the regular 'atrm' program.
Making an SMTP temporary error reliably permanent
2020-03-14
This thread on the postfix-users list identified a minor pitfall in the use of delay_warning_time. If you use a unit smaller than than 'h' for hour, e.g. 'delay_warning_time = 15m', things go a little awry. The warning mail that postfix generates includes the slightly odd statement that "Your message could not be delivered for more than 0 hour(s)" and the postfix log warns about "zero result in delay template". There is no hint to this effect in the man page postconf(5), which offers units down to the second.
Not a severe problem but it did make me wonder: how do you verify how your mail server handles temporary errors returned by remote servers? A temporary error is, by definition, not one that you can count on occurring reliably on demand. What you need is some address to send to like <err451@example.com> that is guaranteed to result in rejection with a 4xx error. I don't know of any such service but managed to cook one up for myself.
On my mail server 'rolly' I added this transport(5) table:
transport_maps = hash:/etc/postfix/transport-map
neon.lan smtp:[fe80::fa59:71ff:fe16:e5d6]
Which means, mail for <anyone@neon.lan> goes to the SMTP server at the given address, which belongs to my home server 'neon.lan' (except I used its real address, not the bogus one I've shown above). neon runs its own postfix instance, normally as a send-only satellite of rolly. To take on its extra task of failing to receive mail, neon's postfix config needed a few tweaks.
inet_interfaces = all smtpd_recipient_restrictions = check_recipient_access hash:/etc/postfix/check-recipient-access
neon's postfix now listens for requests from outside (I set the firewall so that only rolly could make such requests). When a mail comes in, neon checks the recipient against a lookup:
err451@ 451 My hovercraft is full of eels.
From my laptop, I can now send a mail via rolly's submission
service to <err451@neon.lan>; rolly will attempt to send it to
neon; neon will refuse it; and rolly's log will show
451 4.7.1 <err451@neon.lan>:
Recipient address rejected: My hovercraft is full of
eels. (in reply to RCPT TO command)
My new test facility is available only for senders using acrasis.net's submission service. I verified with swaks that an outside client attempting to send to <err451@neon.lan> is rejected with "Relay access denied". For the benefit and amusement of the world, I added an "err451" address to acrasis.net itself:
smtpd_recipient_restrictions = ... check_recipient_access hash:/etc/postfix/check-recipient-inbound
err451@ 451 My hovercraft is full of eels.
Should you wish to send a mail knowing its delivery will fail with a reliably permanent temporary error, feel free to send to <err451@acrasis.net> .
Transferring a domain
2020-02-15
On February 5th my domain registrar, Gandi, informed me by email that I should begin work to "migrate your account ... to the v5 interface". They assumed that I understood what this meant ("As you are no doubt aware...") and gave me a deadline of March 5th. Having no desire to become an unpaid and ill-prepared IT worker for Gandi, I looked into moving my domain elsewhere and decided on Mythic Beasts ('MB' here for short). The process turned out to be reasonably straightforward but not obvious.
Step one, switch off DNSSEC at Gandi. There doesn't appear to be any way to transfer a domain that uses DNSSEC without temporarily disabling it.
Two, in case of messing something up, I switched my contact email addresses at Gandi from acrasis.net addresses to a backup freemail account.
Three, likewise I set my contact email at MB to the freemail address. If I became unable to receive mail at acrasis.net, I would have some chance of repairing the situation by contacting one or other registrar.
Four, copy my DNS records from Gandi's to MB's DNS service.
Five, Gandi's DNS page had sternly advised not changing nameservers for at least two days after disabling DNSSEC. I obeyed, then switched to MB's nameservers. The aim here was to avoid any interval when my domain would 'go dark' in DNS.
Six, acquire the necessary transfer code from Gandi.
Seven, begin the actual transfer at MB, supplying the transfer code. And money.
Eight, respond to the new registrar's email requiring me to confirm contact information.
Nine, switch on DNSSEC at MB. Check everything still works.
Ten, switch my contact email addresses at MB back to acrasis.net.
My ten steps to escaping Gandi took eight days and so far, touch wood, all is well. The steps are just an outline, leaving out numerous tests along the way to verify that my email was still working. I asked MB several questions which they answered promptly and helpfully. I can only hope their excellent support continues and they don't start outsourcing IT work to their customers.
A Third Postfix Pitfall
2019-11-20
This was so perplexing that I sought help on the mailing list. This thread provides the long version of my latest pitfall. The short version is, the postfix documentation is incorrect about smtpd_relay_restrictions and smtpd_recipient_restrictions. Postfix applies the recipient restrictions before the relay restrictions. So if you want to avoid pointless activity on your server, you need to put reject_unauth_destination early on in your recipient restrictions. Mine now consists of -
smtpd_recipient_restrictions = permit_mynetworks, permit_sasl_authenticated, reject_unauth_destination, reject_non_fqdn_recipient, reject_unknown_recipient_domain, reject_unauth_pipelining, reject_unverified_recipient, check_policy_service unix:private/policyd-spf
The unwanted activity might be harmful as well as pointless. Making unnecessary address verification probes will not endear you to the servers concerned and might damage your mail server's reputation.
The purpose of smtpd_relay_restrictions now is unclear. I've left it set anyway as it probably does no harm. I tested with swaks to verify that relay attempts no longer trigger address verification probes.
The grass is starting to look greener on the other side.
Utility meter readings: overengineering for fun and profit
2019-11-07
Well, mostly fun, of a kind. Since domestic energy companies in the UK are highly variable it's a sensible precaution to keep your own notes of meter readings.
I've kept such notes in a text file but that has two drawbacks. It won't compute what your rate of consumption was and it won't guard against clerical errors like transposing digits or getting the date wrong by a week. The obvious solution is of course to write a database-backed application.
My preferred database is PostgreSQL. My one (1) table is accompanied by 1 trigger, 1 view, 2 domains, 2 procedures, 3 types and 6 functions. They'll stop me from entering some silly high or low reading, or dating it in the future and so forth. They also calculate my average daily rate of KWh or cubic metres since the previous reading.
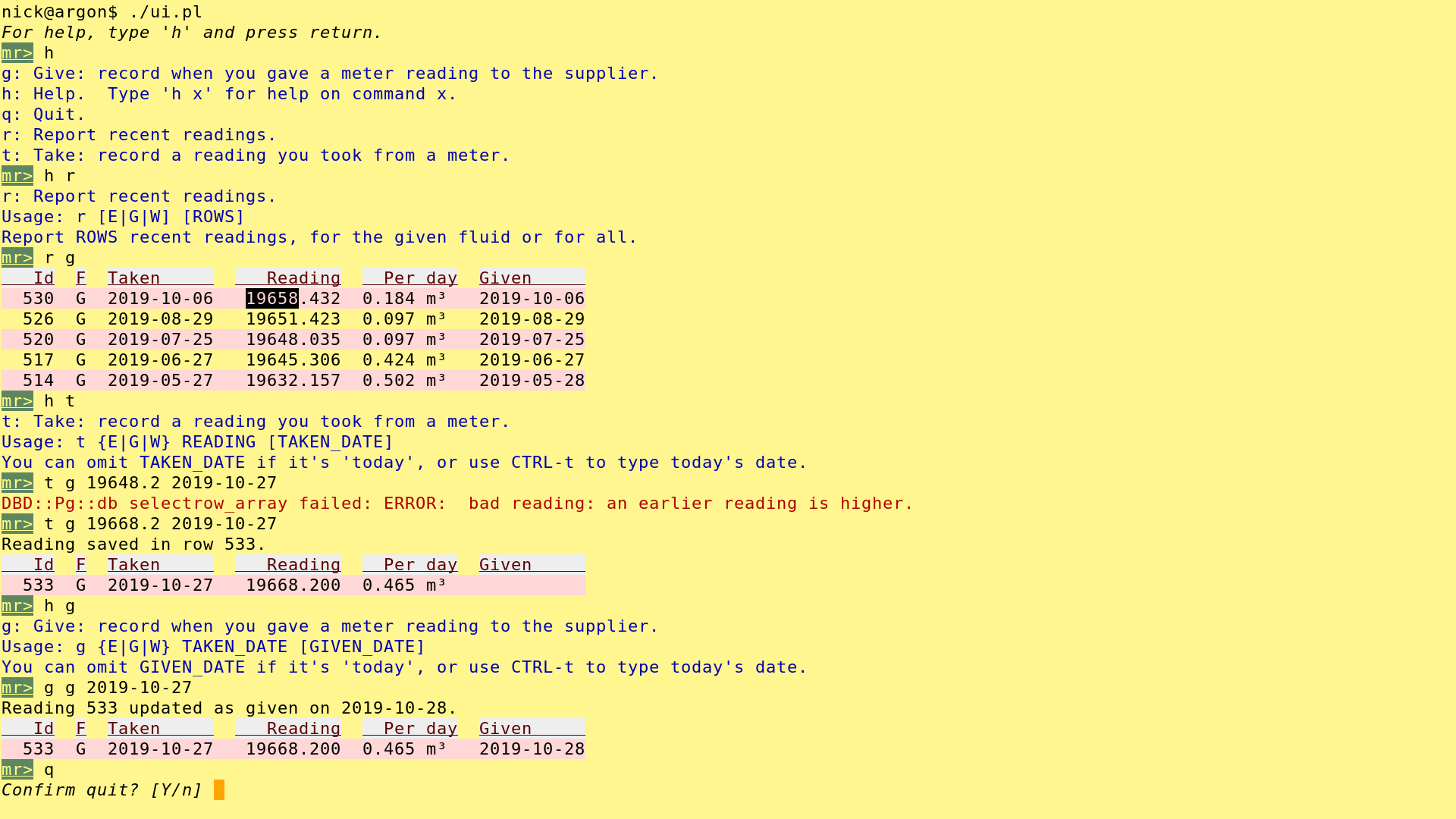
For a user interface, I settled on a command line program written in perl with DBD::Pg, Term::ReadLine::Gnu and Term::ExtendedColor. It provides me with the sumptuous user experience that you can admire here.
{kind=link}
Printing and the "laptop problem"
2019-09-14
On my home server "neon" I've attached a printer by a USB cable, so
that I can use the printer in its capacity as a scanner. The server
runs Debian 10.1. Configuring printing in CUPS was straightforward.
The printer's page, as seen from my laptop, shows its vital statistics
as
Description: Epson Stylus SX445W
Location: World HQ
Driver: Epson Stylus SX445W - CUPS+Gutenprint v5.3.1 (color)
Connection: usb://EPSON/Stylus%20SX440?serial=4E3956593031383497&interface=1
Defaults: job-sheets=none, none media=iso_a4_210x297mmsides=one-sided
How to configure CUPS on my laptop (also Debian 10.1) to use this
printer was not so obvious. The key pieces are the driver ("raw") and
the connection URL. For the URL, none of the suggestions offered by
CUPS's forms would work, nor those found by my web searches.
Eventually I discovered that it wants the same URL as in the caption
above.
Description: Dark plastic box
Location: World HQ
Driver: Local Raw Printer (grayscale, 2-sided printing)
Connection: http://neon:631/printers/neon-usb
Defaults: job-sheets=none, none media=unknown
The alert reader will have noticed "grayscale" and might wonder whether it supports colour printing. It does. I can print from mutt running on neon or from Firefox running on my laptop, and can scan with 'xsane' running on neon over ssh or running on my laptop in conjunction with usbip.
With cheap third-party ink cartridges, this Epson is a reasonable deal for occasional medium-quality printing. An irksome thing however is the printer's behaviour if it decides it's out of ink for any cartridge. It will do nothing, not print in other colours and not even scan.
Two Postfix Pitfalls
2019-09-10
Pitfall the first: add an alias, it doesn't work.
My dentist sends appointment reminders by email, which works best if you actually receive the mail. I'd removed or never added the relevant alias to my postfix configuration, so my server rejected the reminder during the SMTP dialogue. Easily remedied - add the alias to virtual_alias_maps, rerun postmap, reload postfix for good measure, what can go wrong?
It still gets rejected, that's what. Eventually I found a remedy in the LOCAL_RECIPIENT_README. I had neglected to set local_recipient_maps. OK, let's try local_recipient_maps = $virtual_alias_maps.
Success! Now my dental alias was working. But there's a catch. The account to which my aliases resolve, let's call it $me, can no longer receive mail by its own true name. Oops. Solution:
local_recipient_maps = static:$me, $virtual_alias_mapsResult, the aliases and my "true" address all work. (Why nearly all my aliases had worked before, I have no idea.) Now my postfix config must be perfect!
Pitfall the second: remove an alias, it still works.
A week passes. Having switched to a new supplier for some commodity or other, I deleted the alias that I'd provided to the old supplier. So any attempt by my old supplier to send me a special offer just right for me via that alias will be summarily rejected by postfix at SMTP time, right?
Wrong. Postfix accepts it, discovers it can't deliver to that address then promptly returns a bounce message to the sender. This is Not Good as I am now potentially an unwilling participant in backscatter spam.
This proved tougher to track down than pitfall the first. Eventually I discovered that there is a thing called verify(8) by which postfix caches address verification results. It appears that the deleted alias was still considered valid in this cache (see also this thread). I deleted the cache file identified by address_verify_map and added this to main.cf:
address_verify_map =(meaning, no persistent cache for me, thank you) and restarted postfix. Result, my former supplier's alias is properly gone: mail to the address is rejected at SMTP time. Now my postfix config must be perfect!
FireHOL, Fail2ban and ipsets
2019-02-09
IP sets are a fast way to test whether an IP address is present in an indefinitely large number of addresses. FireHOL and Fail2ban both support them. Fail2ban ships with an "action" config file that creates an ipset and adds an iptables rule when fail2ban starts. On shutdown it removes the rule and destroys the ip set.
I decided not to use that fail2ban action file. Fail2ban places its rules right at the start of the INPUT chain, which means that every packet of every legitimate connection has to be tested against the rule before the packet is accepted.
Instead, firehol takes care of creating the ipset and rule, placing the rule after tests for established connections. It does mean (I think) that hostile connections will be allowed to complete before the ban takes effect, which I'm accepting. Fail2ban's role is therefore only to add and remove entries in the set.
FireHOL config for ipsets
Here is how my firehol config on my VPS creates the sets and uses them, for HTTP.
interface ... ... ipv4 ipset create f2b-http hash:ip timeout 6000 ipv6 ipset create f2b-http6 hash:ip timeout 6000 server4 http drop src ipset:f2b-http log "f2b-http" server6 http drop src ipset:f2b-http6 log "f2b-http6" ...
Fail2ban action file for ipsets
Fail2ban requires a new "action" file to make it do less with ipsets. My new file is based on /etc/fail2ban/action.d/iptables-ipset-proto6.conf. Among other things, it does nothing for "actionstart" since firehol takes care of creating the sets and rules now.
[INCLUDES] before = iptables-common.conf [Definition] actionstart = actionflush = ipset flush <ipmset> actionstop = <actionflush> actionban = ipset add <ipmset> <ip> timeout <bantime> -exist actionunban = ipset del <ipmset> <ip> -exist [Init] # 12 hours == 43200 seconds bantime = 43200 ipmset = f2b-<name> familyopt = [Init?family=inet6] ipmset = f2b-<name>6 familyopt = <sp>family inet6
Fail2ban jail and filter
Here's how one of my 'jails' uses the ipsets for HTTP. This one is an addition since my initial configuration of fail2ban. It bans any visitor that uses a host name other than "www.acrasis.net" or "acrasis.net".
[007-http-wronghost] enabled = true filter = 007-http-wronghost action = aaa-donym-ipset[name=http, bantime=864000] logpath = /var/log/lighttpd/access.log maxretry = 1 bantime = 864000
The bantime has to be supplied twice. In this jail I've made it ten days instead of the previous one day, greatly increasing the number of web miscreants included in my ban. Here's the filter.
[Definition] failregex =ignoreregex = ^[^ ]+ (www\.)?acrasis.net
A munin graph of "Hosts blacklisted" showing the before and after of my switch to ipsets on February 7th:

Munin
2019-01-30
My home server "neon" now offers me pretty coloured graphs about its state. More usefully it shows a similar set of graphs for my VPS, "rolly". Munin provides a master program that runs on neon and a node program that runs on each of neon and rolly. The master periodically asks each node for its data and formats that data into graphs that it writes to neon's file system as HTML files.
munin-node on neon
This is on the same host as the master so it listens for its master's voice on localhost, with square brackets for the ipv6 address.
# Mostly as installed, so these are only the highlights: host_name neon host [::1] port 4949
munin-node on rolly
Apart from host_name, /etc/munin/munin-node.conf is the same as on neon. It too listens on ipv6 localhost because I didn't want to open another port. Instead I use a tunnel.
The tunnel
The tunnels I added for ssh from neon to rolly gain another bore, in my ssh config on neon.
Host rolly-tunnels ... LocalForward [::1]:49490 localhost:4949
munin master on neon
The master config is as installed except I commented out the entry for localhost. I prefer to use config fragments under munin-conf.d/.
[neon]
address [::1]
# Use the port number to distinguish rolly from neon.
[rolly]
address [::1]
port 49490
The web server
This bit of lighttpd config on neon lets me view the munin graphs from a browser:
$HTTP["host"] == "munin.lan" {
server.document-root = "/var/cache/munin/www"
}
Then on my laptop I added a /etc/hosts entry for munin.lan. Now I can point my browser to http://munin.lan/ and see my munin overview page with links for neon and rolly.

Monitoring mail rejections
2018-08-02
Receiving spam or other hostile mail is bad but rejecting legitimate mail is worse. For a while I used pflogsumm to mail me a daily summary of what my mail server is up to. Two things I found: that I was mostly interested in delivery attempts that were rejected; and that pflogsumm misses rejections if postscreen is involved.
It's unlikely pflogsumm will be fixed (e.g. #743570). So I wrote my own log file analyser. If I reject your legitimate mail at least I'll know about it. Probably.
ssh tunnels for email
2018-07-14
My local mutt and postfix are configured to use ssh tunnels for imaps and submission respectively. That means my remote mail server can close two more ports. Here's the ssh host for the tunnels from my home computer to my remote mail server "rolly".
Host rolly-tunnels Hostname rolly ServerAliveCountMax 6 ServerAliveInterval 5 LocalForward [::1]:9930 localhost:993 LocalForward [::1]:5870 localhost:587
If the ssh client process loses contact for more than 30s it will exit, thanks to the ServerAlive parameters. To take care of restarting it, I use autossh.
if ! pgrep -f 'ssh .+ rolly-tunnels' > /dev/null; then
autossh -M 0 -fN rolly-tunnels
fi
By that point in ~/.bash_login, Keychain has taken care of adding the necessary key to ssh-agent(1) so it doesn't need me for the passphrase. If for example I need to restart my home Internet router, I can count on the tunnels coming back afterwards without any intervention from me.
Then we tell mutt to use the tunnel,
set folder=imaps://localhost:9930/
And likewise my local instance of postfix,
relayhost = [localhost]:5870
On the server, that leaves only four ports open to the world: http, smtp, smtps and ssh. Actually fewer than that since if I'm on a fixed ip address for a while I can open the server's ssh port only to that address. So far this has worked well and prevents attackers from trying to brute-force my email credentials.
fail2ban and HTTP
2018-04-22
Bots trying mischief on port 80:
176.31.104.175 www.acrasis.net - [19/Apr/2018:20:10:24 +0100] "GET /components/com_b2jcontact/css/b2jcontact.css HTTP/1.0" 404 345 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" 87.63.253.50 195.201.29.227:80 - [20/Apr/2018:17:46:32 +0100] "POST /wls-wsat/CoordinatorPortType HTTP/1.1" 404 345 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" 87.63.253.50 195.201.29.227 - [20/Apr/2018:17:46:33 +0100] "GET /wp-login.php HTTP/1.1" 404 345 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
No good can come of those requests. While I don't think my web server is likely to be cracked by them, some countermeasures were in order. Fail2ban is a popular way of monitoring log files for misbehaviour and doing something to block it, typically by adding a firewall rule.
Fail2ban has numerous ready-made configs but not for HTTP bots. So I added my own. It seeks to drop packets to port 80 from clients that do either of these:
- get too many 404s (actually any 4xx or 5xx) with GET, HEAD, etc
- do a single POST (or any other "update-ish" method)
This mostly works, in that in the fail2ban log I can see bans at the rate of 10 or 20 a day. It isn't perfect, however.
Serveral times I've seen a series of GETs resulting in 404s, well over the number that should trigger a ban. But it seems they don't trigger a ban if they all have the same timestamp.
Fail2ban's ipv6 support is evolving and in the version I'm running, 0.10.2, it bans only the single ipv6 address. Since the attacker probably has thousands of ipv6 addresses available, it would be better to ban a range.
Something to bear in mind is that if you think your site might have dead links internally (page foo links to page bar but bar isn't there any more) then a ban on GETting 404s might keep out legitimate clients.
screen and tmux
2018-04-20
After years of using screen, I tried tmux in order to get italics (who wouldn't want italics in his terminal?). This proved more difficult than expected: not answered in any of several tutorials, the FAQ and man pages was "how do you configure tmux so that it starts a set of programs for you?" In screen, you do this with the 'screen' configuration command.
In the tmux world it seems that you accomplish this with commands from outside of tmux, i.e. in a shell script, or at least that's how I got it to work. So in case it helps anyone else here is a slightly redacted version of my tmux config which comes complete with the shell script and with a poor man's network traffic monitoring script.